Since September 2018, I have been developing software to lemmatize historical lexicons. I was given two projects when developing software for lemmatization: the first creates a database that allows bibliographic information from early modern lexicons to be extracted easily; and the second develops software that would automatically lemmatize lexicons based on the modern-day spelling of words from the Oxford English Dictionary. The software for lemmatization used bibliographic information extracted from my database.
I have developed programs in Python to automatically find the difference between OED and historical lexicons, which would enable lexicons to be lemmatized semi-automatically. OED is a useful resource since it contains extensive information on modern English headwords, such as their part of speech and date on their first and last occurrence. OED has given LEME an Excel file of data, which I used to build a relational database to more easily access the data. A relational database organizes data into one or more tables of columns and rows, with a unique key identifying each row.[1] I inserted all the OED word-entries into the database by using their unique URL as their ID.
For my first project, I created a database for historical lexicons that allows information to be extracted based on the date of the lexicon. We wanted to find word-entries that are in the historical dictionaries but not in the OED, as well as word-entries that antedate or postdate the OED citations. OED cites the first and last occurrence of a headword, but historical dictionaries also provide their own date of publication. By comparing these dates, we can determine whether a historical lexicon antedates or postdates headwords cited by the OED. The date of the first and last occurrence of a word in the OED can be simply extracted by a SQL command. To accomplish this, I extracted lexemes from word-entries in XML files of historical dictionaries. A unique LEME ID is also needed to create the tables. At first, I tried to use Python XML parsing tools to extract the information. However, I found that not all files were well formatted so I needed to validate and modify them before extracting word-entries. I had to write programs that automatically corrected invalid XML elements. Then, I decided to consider the original XML files as regular TXT files, which means that I did not use built-in XML functions in Python; I wrote my own functions to delete XML tags so that only word-entries and their part of speech remained in the TXT files. As a result, I could easily add word-entries with parts of speech to the database I built, and I used SQL queries to extract the information we needed. Once we added word-entries into the database, we could gather information through one simple command. For example, if we want to find word-entries that antedate the OED, we could use a simple SQL command such as
SELECT leme.wordentry, leme.pos FROM leme inner join oed on oed.headword=leme.wordentry and oed.pos=leme.pos where leme.date < oed,first_date.
Given a historical dictionary file, the program could add word-entries into the database and generate report files.
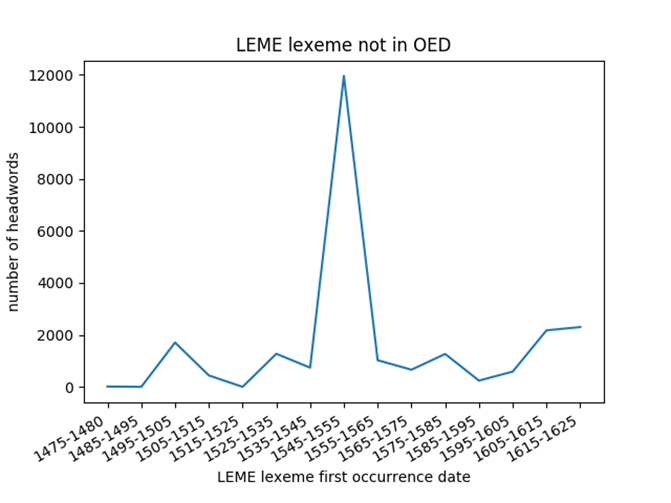
Furthermore, individual report files for historical dictionaries are insufficient for forming any conclusions, but graphs may be helpful for comparing several lexicons across different periods of time. The database allows us to discover the number of antedatings, postdatings, and LEME lexemes not in the OED during a specific period. For example, we could generate graphs of LEME lexemes not in the OED (Figure 1).
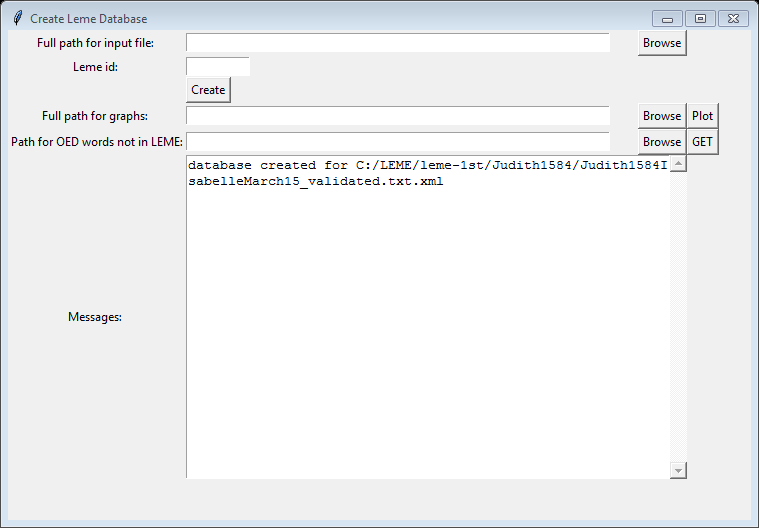
I also created a user interface (UI) for this program (Figure 2). The program has two features: one, creating tables for each dictionary; and two, creating graphs. To create tables for each dictionary, we give the program the full path of the dictionary file and its LEME id, and then click “Create.” Now, the program can automatically parse the file, add new word-entries into the database, and generate report files into the same directory as the input. Once the program finishes creating tables for dictionary files, a message would inform the user whether the process has successfully finished. Clicking “Plot” automatically plots the graph. When given the desired output path, graphs would be created in that directory. (Figure 3)
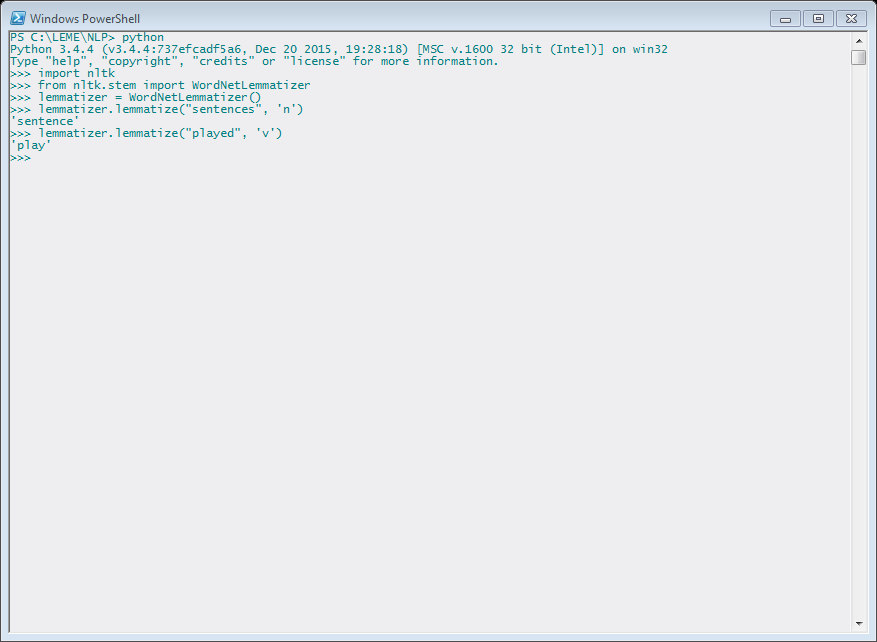
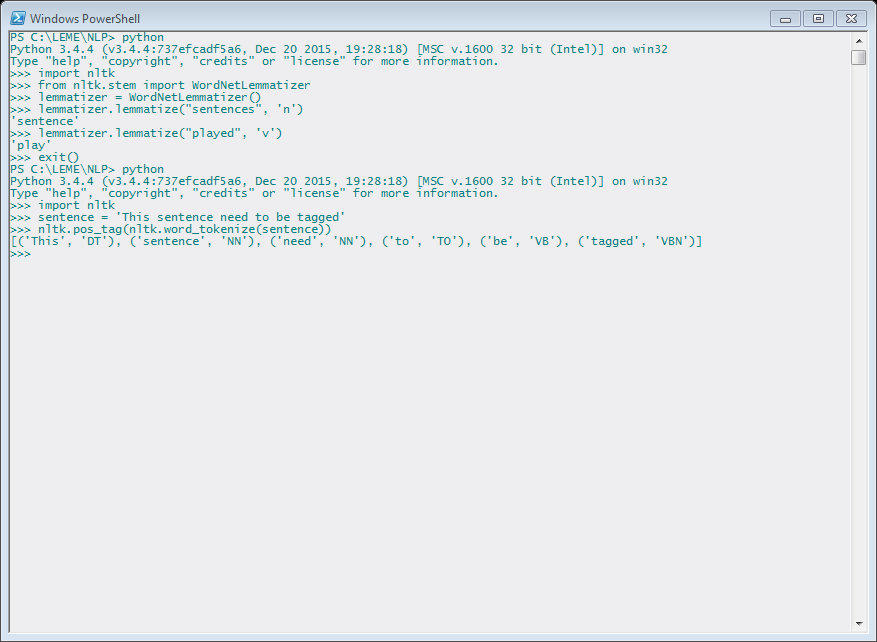
The second project is a Natural Language Processing project on automatically lemmatizing lexicons based on the OED. I started with studying Python NLP tools and papers on string matching. I benefited from Natural Language Processing for Historical Texts, edited by Graeme Hirst. The book emphasizes that the spelling of words varies frequently, depending on the grammar and historical period in which the word occurs. To address the variance of spelling, word-entries need to be normalized by standardizing grammar and spelling. In Python, there is a toolkit called NLTK, which provides text processing libraries for tokenization, stemming, tagging, parsing and so on.[2] Given a sentence, NLTK could automatically recognize the root word (Figure 4) or add part of speech tags (Figure 5).
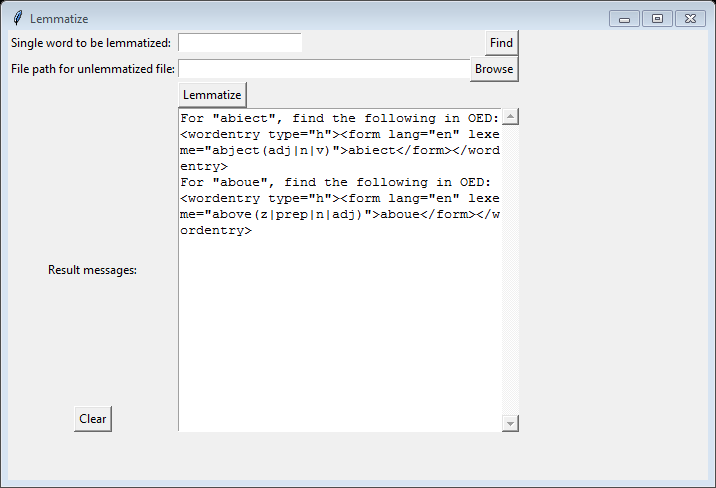
However, historical spelling is not the same as modern spelling, as there are some rules and variations. Referring to an OED blog post on early modern English pronunciation and spelling, I used regular expressions to implement its rules so that historical spelling could be recognized and modified.[3] As a result, the program can recognize some simple historical variations. For example, ‘abiect’ is recognized as ‘abject’, and ‘aboue’ is recognized as ‘above’ (Figure 6). However, there are more variations than simple rules. Consequently, I tried to find the most similar word in the dictionary by edit distance and longest common subsequence. Edit distance is way to quantify how dissimilar two strings are.[4] It measures the minimum number of operations (including insertions, deletions, and substitutions) required to change one word to another. Instead of regular edit distance, I used Damerau-Levenshtein distance, which includes the transposition of two adjacent characters as an operation. Damerau-Levenshtein distance allows us to accommodate the shifting of historical spellings into modern spellings of words. For example, the program registers that ‘abel’ could be a historical spelling for ‘able’. Longest common subsequence helps by checking the order of the characters in the original strings. If I find more than one similar word in the dictionary, I will list all of them. For example, although ‘heereafter’ is not in the OED, the program can find ‘thereafter, whereafter, hereafter’ as similar words.
I then created a UI to run this program. It could lemmatize a single word or a dictionary file (Figure 7).
However, this program runs slow for large files since it
guesses the words by edit distance and compares the results with 97,800 OED
word-entries. I came up with a way to improve the speed by running the program
in multi-thread. In multi-thread, I can lemmatize several words at the same
time, which drastically reduces the time it takes for the program to run. Since
lemmatizing a single word takes around three minutes, without multi-thread, lemmatizing twenty
word-entries would take around one hour. With multi-thread, we could lemmatize five
word-entries simultaneously, and the entire process would take around twelve
minutes. We could also run the program on a more powerful computer or a virtual
machine to improve the efficiency.
[1] “Relational database,” Wikipedia, accessed June 6, 2019, https://en.wikipedia.org/wiki/Relational_database.
[2] Steven Bird, Edward Loper and Ewan Klein, Natural Language Processing with Python (O’Reilly Media Inc., 2009).
[3] “Early Modern English Pronunciation and Spelling,” OED, accessed June 6, 2019, https://public.oed.com/blog/early-modern-english-pronunciation-and-spelling/
[4] “Edit Distance,” Wikipedia, accessed June 6, 2019, https://en.wikipedia.org/wiki/Edit_distance.